
Содержание
Уже более двух десятилетий капча используется в качестве ключевой стратегии борьбы со спамом и нежелательным онлайн-трафиком. Эти привычные задачи, часто включающие в себя определение простых слов или изображений, служат базовым тестом, позволяющим отличить человека от компьютера.
Оригинальный термин CAPTCHA расшифровывается как Completely Automated Public Turing Test to tell Computers and Humans Apart — «полностью автоматизированный тест Тьюринга для отличия компьютера от человека». Первоначально тест Тьюринга проверял, способна ли машина обмануть человека, заставив того поверить, что перед ним человек. Если машина проходит этот тест, то, по мнению математика Алана Тьюринга, она разумна.
Теперь же капча используется для того, чтобы не допустить рассылки спама или нежелательной активности пользователей. Разоблачение машины означает ее недопуск на тот или иной сайт или к определенным активностям. Изучая эволюцию и нюансы технологии капчи, можно получить новое представление о развивающихся взаимодействиях между людьми и компьютерами и о том, как эта динамика интегрируется в цифровые и интернет-системы.
Возникнув на основе непатентованных криптографических разработок со спорными претензиями на авторство, она превратилась в оживленную экосистему исследователей безопасности и хакеров, которые постоянно расширяют границы технологий распознавания изображений и анализа документов. В конце концов эти инновации были объединены под контролем компании Alphabet, ранее известной как Google.
Предтечи капчи
В неопубликованной статье израильского криптографа Мони Наора «Проверка человека в цикле, или Идентификация через тест Тьюринга» (1996) есть один малозаметный подраздел. В нем можно найти краткое упоминание, которое, вероятно, представляет собой самую раннюю концепцию того, что впоследствии станет капчей. Наор, известный своими работами в области визуальной криптографии, большую часть своей статьи посвятил решению проблемы растущего спама в интернете, затрагивающего такие сервисы, как электронная почта и поисковые системы.
Предложенное им решение переработало тест Тьюринга, введя в него задачу идентификации контента, например определение пола или обнаружение наготы на изображениях. Эти задачи, простые для человека, но сложные для более простых ботов эпохи 1990-х, будут взяты из огромного, заранее определенного набора вопросов и ответов.
Наор рассуждал о возможности полностью автоматизировать этот процесс проверки человека в цикле (human in the loop), предлагая перейти к тому, чтобы за аутентификацией следил компьютер, а не человек, и намекая на будущее, в котором программа создания теста будет общедоступной.
Хотя сам термин «капча» появился лишь много лет спустя, краткие заметки Наора заложили основу для этой системы: автоматические тесты, открытый код и данные, вдохновленные тестом Тьюринга, направленные на различение пользователей-людей и компьютеров.
Вскоре после первоначального предложения Наора в 1996 году команда из Digital Equipment Corporation (DEC), ничего не зная о проекте Наора, представила механизм защиты онлайн-опроса для будущих президентских выборов в США. Они разработали систему, в которой пользователи должны были распознать искаженный американский флаг на веб-странице опроса, чтобы предотвратить многократное голосование. Это была ранняя попытка пресечь цифровые манипуляции. Хотя эту систему можно было обойти, обладая определенными техническими навыками, она выполнила свою задачу, предотвратив массовое нарушение голосования.
В следующем году DEC столкнулась с еще одной проблемой, связанной с поисковой системой AltaVista, из-за манипуляций с результатами поиска посредством использования функции Add URL. Вдохновившись ограничениями технологии оптического распознавания символов (OCR), которая не справлялась с искаженными текстами, Андрей Бродер и его команда разработали решение. Они создали головоломки, которые генерировали случайные строки искаженных символов, и предлагали пользователям решить их, чтобы воспользоваться функцией Add URL. Этот метод позволил сократить количество спама на 95%.
Тем временем соревнование между студентами Массачусетского технологического института (MIT) и Университета Карнеги — Меллона (CMU) в онлайн-блоге Slashdot показало уязвимость интернет-опросов для скриптов автоматического голосования. Луис фон Ан, тогда аспирант CMU, которого консультировал известный криптограф Мануэль Блюм, сыграл решающую роль в развитии проекта капчи. Благодаря его работе проект превратился из подхода, позволяющего отличить человека от бота, в более тонкую реляционную модель, которая использовала капчу как для обеспечения безопасности, так и для решения задач, таких как оцифровка текстов и улучшение ИИ с помощью человеческих вычислений. Эта эволюция ознаменовала собой переход к мерам безопасности в интернете, к системам, которые не только обеспечивают безопасность цифрового пространства, но и используют взаимодействие людей для более широкого технологического прогресса.
Виды капчи
Короткая статья Луиса фон Ана и его коллег Мануэля Блюма и Джона Лэнгфорда «Отличие человека от компьютера (автоматически), или Как ленивые криптографы создают ИИ» дает классификацию существовавших тогда типов капчи и завершается перспективными предложениями. В начале документа рассматриваются четыре основные конструкции, которые воплощают подход, где определенная информация либо скрыта, либо рандомизирована, чтобы отличить пользователей-людей от автоматизированных ботов. Всего они выделили четыре вида капчи.
1. GIMPY
GIMPY выбирает семь слов из словаря и выводит на экран искаженное изображение с этими словами. Затем GIMPY предлагает пользователю тест, состоящий из искаженной картинки и указания ввести три слова, появившиеся на изображении. Учитывая типы деформаций, которые использует GIMPY, большинство людей могут прочитать слова, в то время как компьютерные программы этого сделать не могут.

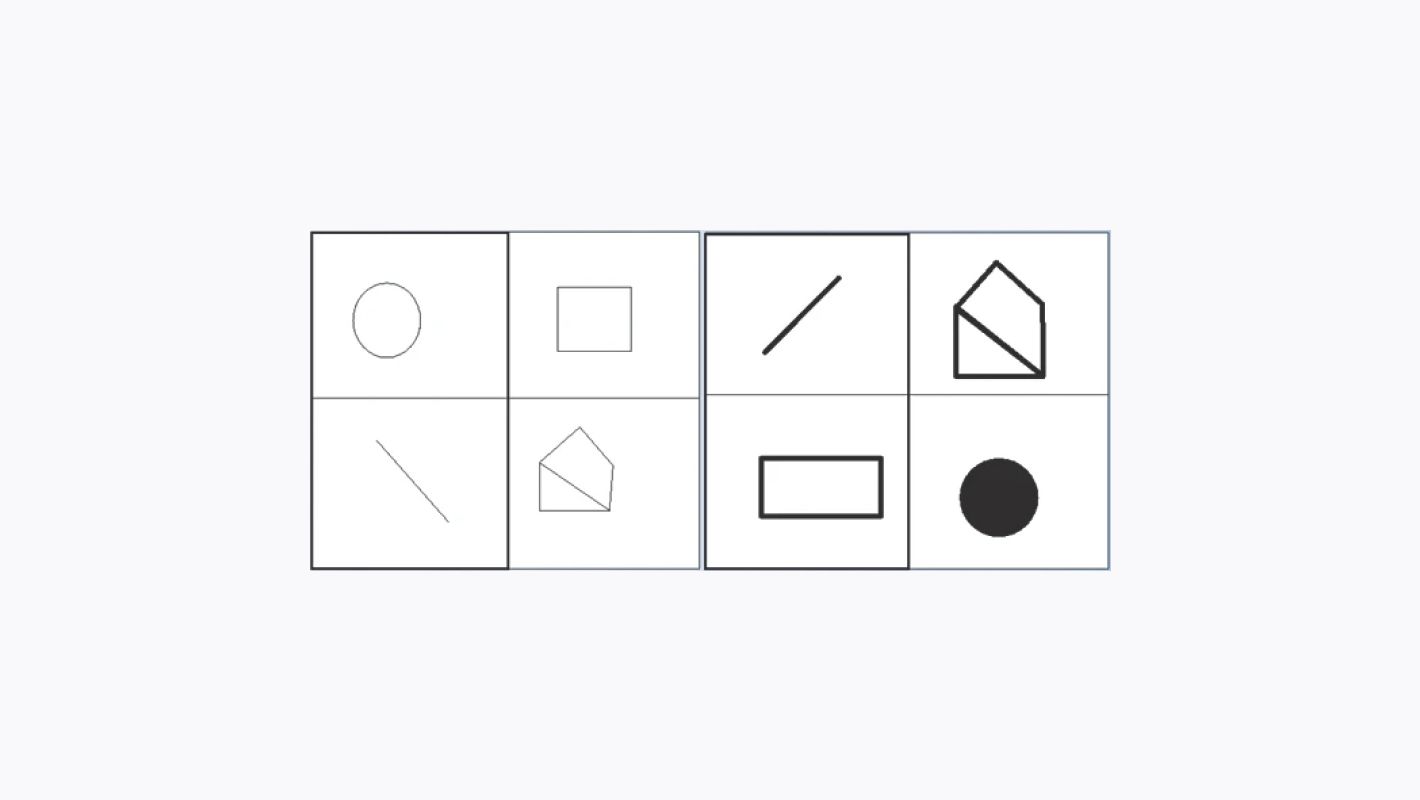
2. BONGO
Просит пользователя решить задачу по визуальному распознаванию образов. В частности, она отображает две серии блоков — левую и правую. Блоки в левой серии отличаются от блоков в правой, и пользователь должен найти характеристику, которая их отличает.
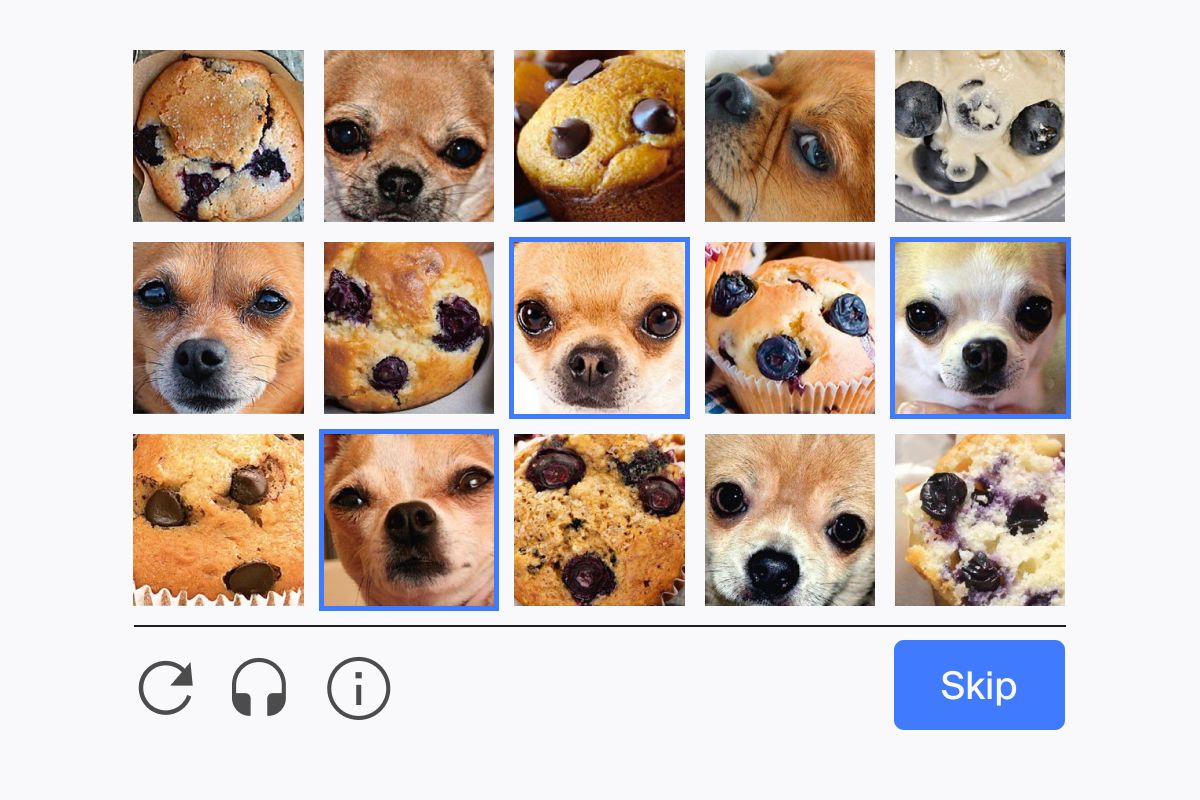
3. PIX
Еще один пример капчи — программа, имеющая большую базу данных помеченных изображений. Все эти изображения должны быть картинками конкретных объектов (лошадь, стол, дом, цветок и т. д.). Программа выбирает объект случайным образом, находит шесть изображений этого объекта из своей базы данных, предъявляет их пользователю и задает вопрос: «Что изображено на этих картинках?».
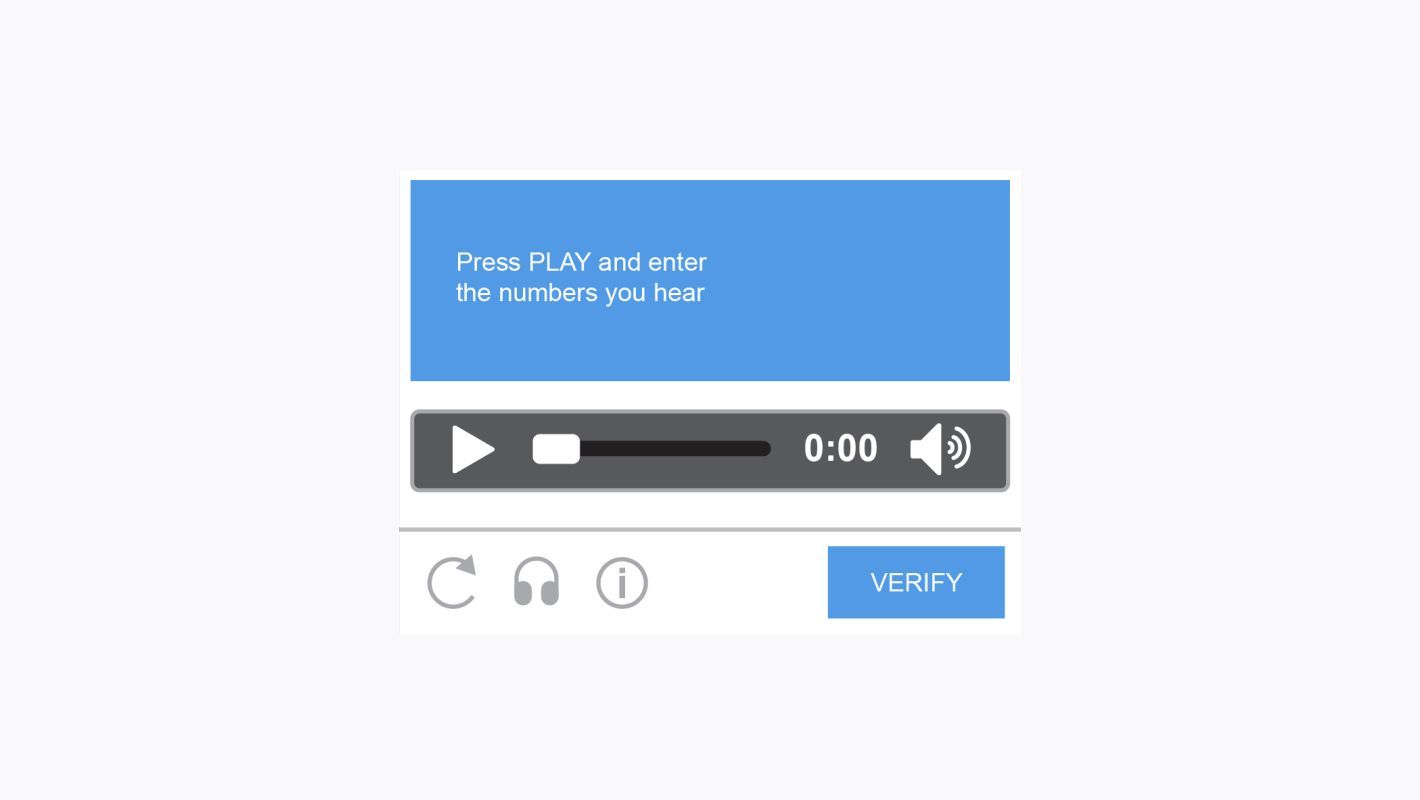
4. ECO
Это звуковая капча. Программа выбирает слово или случайную последовательность цифр, преобразует их в звуковой файл и искажает его. Затем она представляет искаженный звук пользователю и просит его ввести звучащие знаки.
В отчете предлагаются две идеи, наводящие на размышления. Во-первых, в нем утверждается, что успешное решение проблем капчи может быть приравнено к преодолению сложных, нерешенных проблем в ИИ. Тем самым эффективность капчи связывается с прогрессом в области искусственного разума. Чем сложнее капча, тем более разумным должен быть бот, разгадывающий головоломки.
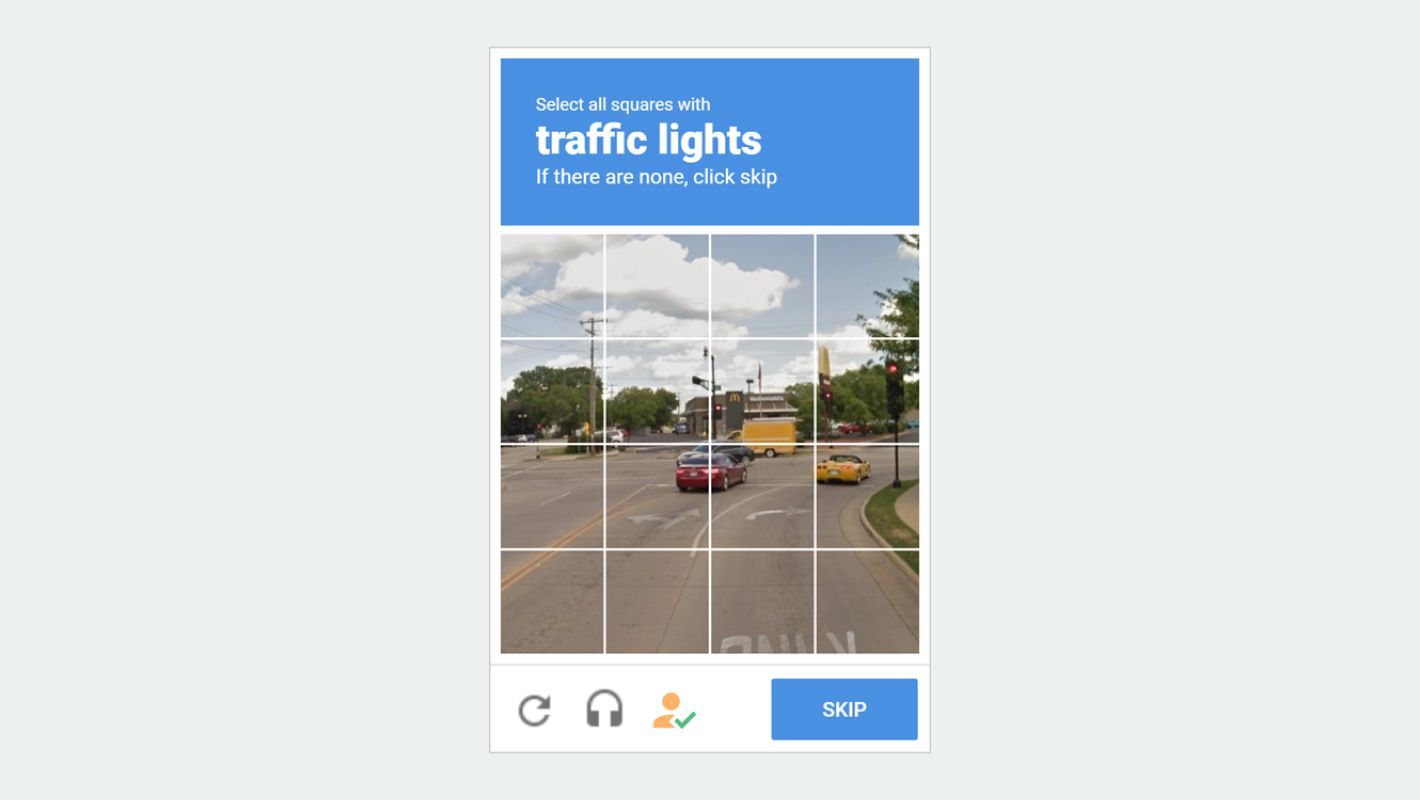
Например, reCAPTCHA, один из самых распространенных современных типов капчи, использует задачи классификации изображений или текста, которые помогают в обучении алгоритмов ИИ Google. Когда пользователи определяют и классифицируют изображения (светофоры, пешеходные переходы или витрины магазинов), они непреднамеренно предоставляют маркированные данные, которые могут быть использованы при обучении моделей машинного обучения для задач распознавания изображений.
Во-вторых, авторы черпали вдохновение в проекте SETI@home. Этот проект использует незадействованные вычислительные мощности персональных компьютеров по всему миру для анализа астрономических данных. SETI@home, как считал Луис фон Ан и соавторы, предлагает краудсорсинговую модель, в которой пользователи интернета вносят вклад в значимые проекты, такие как оцифровка коллекции библиотеки Конгресса, используя свои вычислительные ресурсы, и на добровольных началах. Это предложение могло расширить полезность капчи за пределы обеспечения безопасности, представляя ее как средство использования человеческих вычислительных усилий для более масштабных научных и культурных начинаний.
ESP Game и переход к краудсорсингу
В 2003 году Луис фон Ан и Лорен Даббиш из Университета Карнеги — Меллона запустили игру ESP Game, поставив перед собой амбициозную цель — маркировать каждое изображение в интернете. Эта игра, превратив задачу присвоения семантических меток картинкам в увлекательное занятие, решила значительную потребность в метках изображений для доступности преобразования текста в речь, повышения точности поиска изображений, модерации контента и создания больших наборов данных для обучения ИИ.
Игроки разбивались на пары в случайном порядке, и им предлагалось описать одну и ту же картинку, не зная ответов другого. При совпадении описаний они зарабатывали очки, создавая соревновательную, но в то же время командную среду. Этот инновационный подход не только ускорил процесс маркировки, но и позволил обойтись без больших затрат, обычно связанных с такими масштабными мероприятиями. Всего за четыре месяца после запуска игры было создано более миллиона меток для почти 300 000 изображений, а к 2005 году общее количество меток превысило десять миллионов.
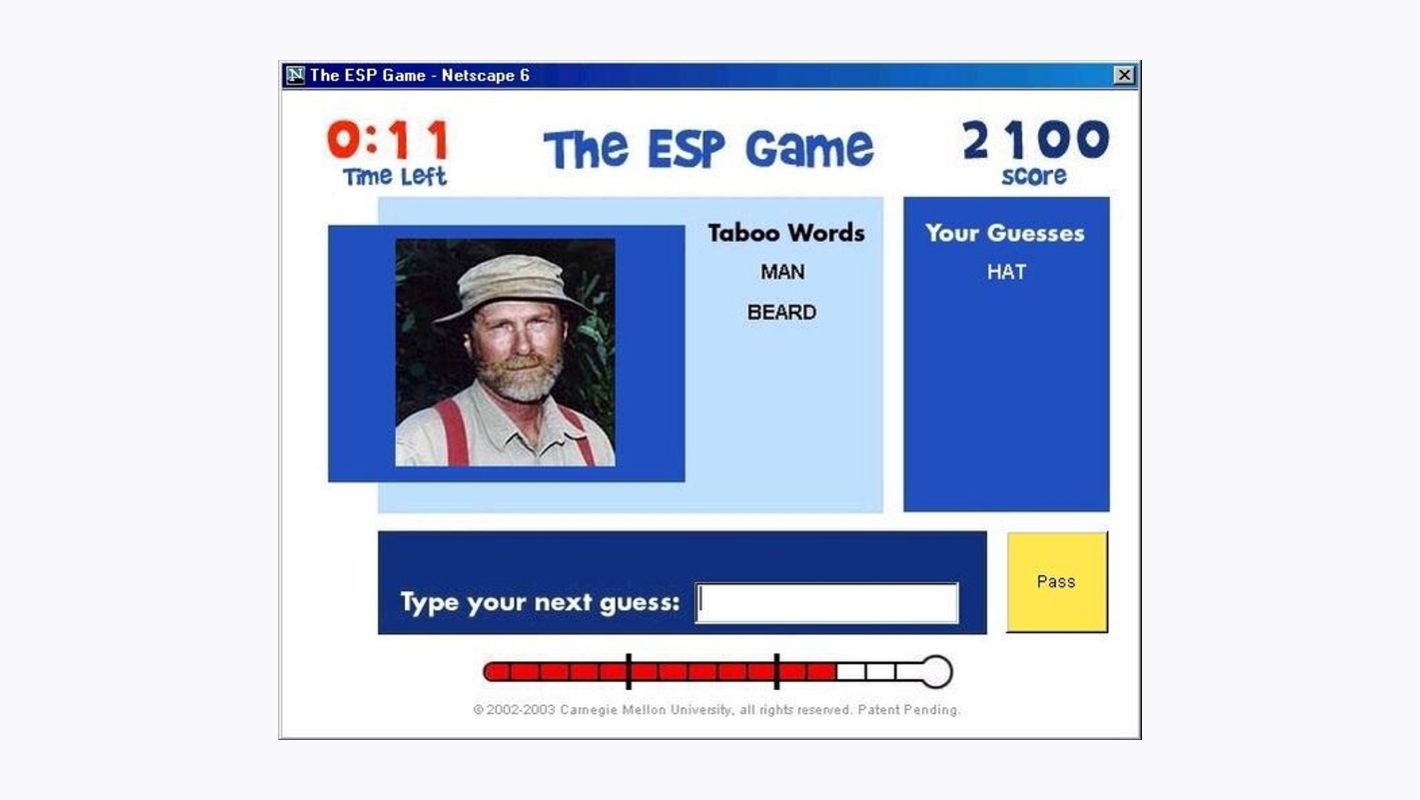
ESP Game представляла собой отход от традиционных систем капчи, которые полагались на то, чтобы отличить человека от бота по его способности интерпретировать искаженный контент. Вместо этого она использовала коллективный интеллект пользователей интернета для достижения общей цели, оценивая их вклад на основе консенсуса и сотрудничества, а не криптографических мер безопасности.
Этот метод краудсорсинга для машинного обучения предвосхитил возможности таких платформ, как Amazon Mechanical Turk, и продемонстрировал переход от защиты контента к вовлечению людей и машин в совместное выполнение задач. Успех и методология ESP Game подчеркнули потенциал реляционных моделей, в которых переплетаются человеческий интеллект и вычислительные процессы, заложив основу для будущих разработок в технологии капчи.
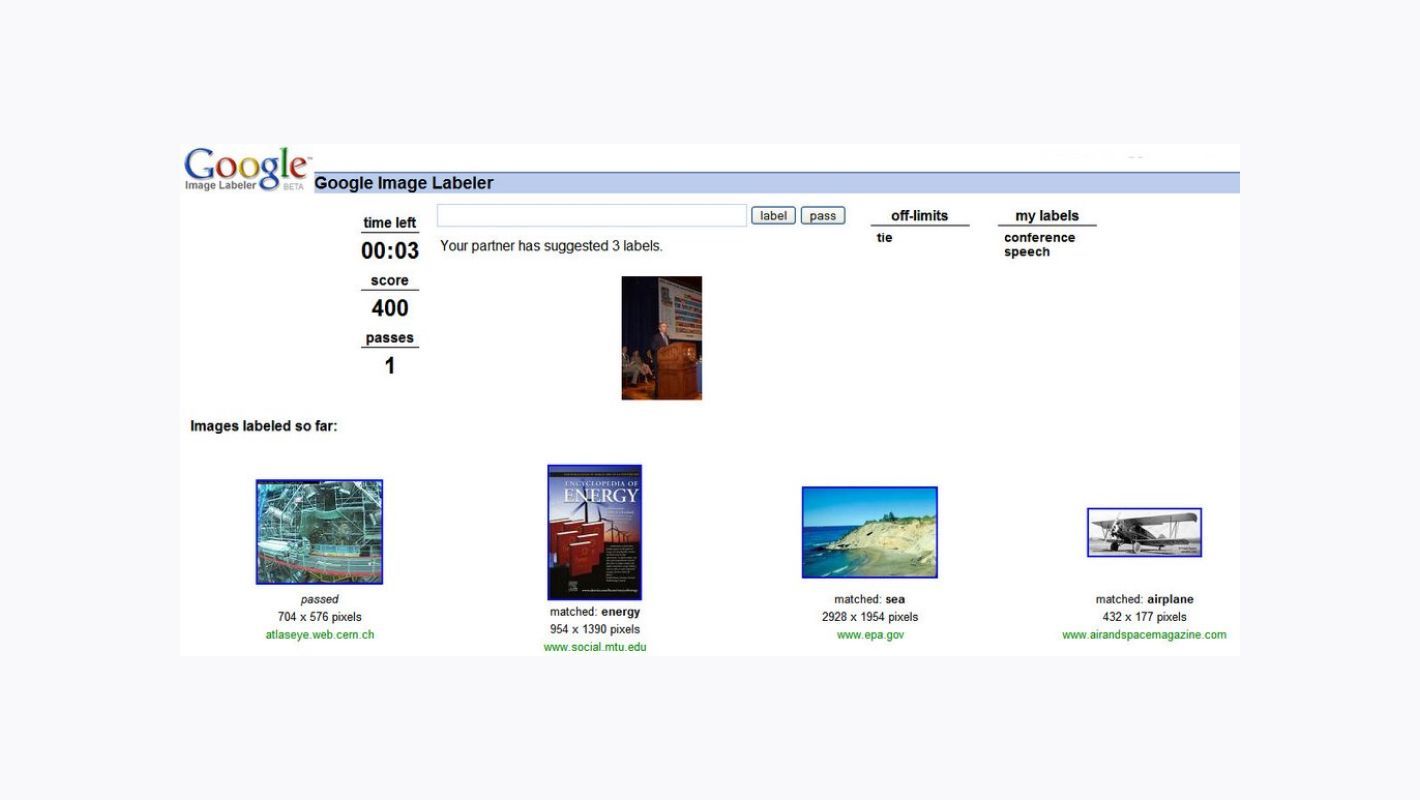
В июле 2006 года Google пригласила Луиса фон Ана, чтобы тот рассказал группе менеджеров и инженеров компании о своих разработках. Вскоре после этой презентации Google приобрела права на программное обеспечение, лежащее в основе ESP Game, и запустила Google Image Labeler — платформу, очень похожую на оригинальную игру фон Ана. Цель этой игры — повысить точность поиска изображений в Google, предложив игрокам маркировать картинки с помощью специального онлайн-интерфейса. Этот подход, использующий совместные усилия для достижения консенсуса по содержанию изображений, обрел большую популярность. К 2008 году эта инициатива собрала более 50 миллионов меток изображений от более чем 200 000 пользователей.
Превращение в reCAPTCHA
Опираясь на этот успех, Луис фон Ан в 2007 году представил проект reCAPTCHA. Этот новый проект был очень амбициозным и предполагал использование ежедневных усилий миллионов людей, решающих капчу в интернете, для более важных целей. В отличие от традиционной капчи в reCAPTCHA использовались тексты из проектов по оцифровке, таких как Google Books и Internet Archive. Это тексты, часто страдающие от физических дефектов или уникальных особенностей дизайна, которые мешали технологиям оптического распознавания символов (OCR).
reCAPTCHA представляла пользователям пару слов: одно уже расшифровано с помощью OCR, а второе только ждет идентификации. Этот метод не только проверял «человечность» пользователя, но и использовал его данные для оцифровки текста, превращая меру безопасности в инструмент совместной работы над глобальным цифровым архивом. Эта инновация оказалась очень важной, поскольку идентификация неизвестного слова основывалась на консенсусе пользователей, а не на предопределенных ответах. Все это ознаменовало переход от традиционных методов капчи к более интерактивному и продуктивному подходу.
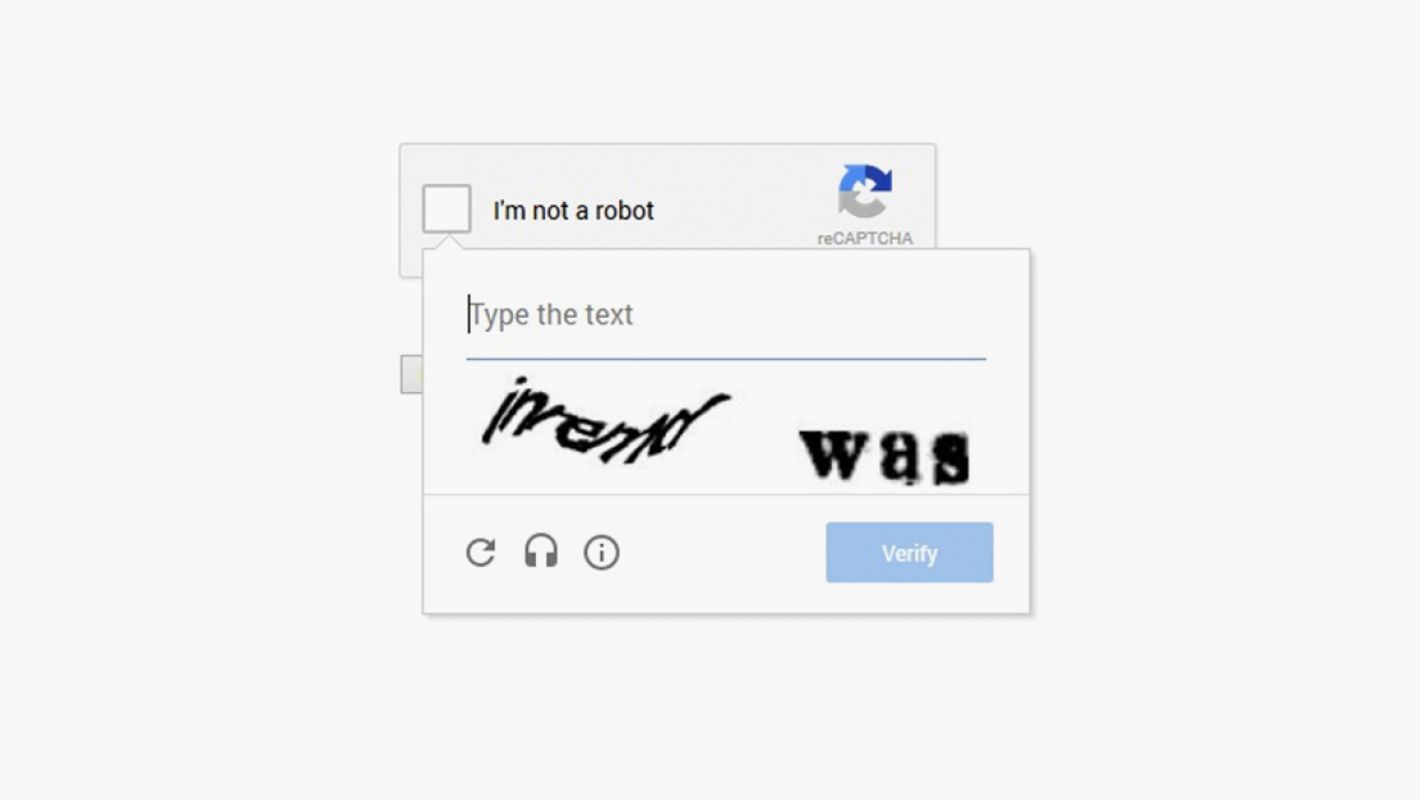
reCAPTCHA представляет собой эволюцию по сравнению с традиционным подходом, который полагается на генерацию случайностей, чтобы скрыть информацию от автоматических систем. Вместо этого задача состоит не только в идентификации фрагмента контента, но и в понимании того, как соотносятся между собой несколько интерпретаций этого контента. Эта система не скрывает информацию, как секрет, который нужно раскрыть, а собирает данные от разных пользователей, чтобы идентифицировать искаженный текст.
Когда пользователи последовательно соглашаются с интерпретацией непонятного слова, этот консенсус позволяет распознать и оцифровать его. В результате совместных усилий неразборчивые фрагменты текста превращаются в разборчивый контент, что улучшает процесс оцифровки таких материалов, как архивы New York Times и библиотека Google Books.
К 2009 году Google приобрела reCAPTCHA, расширив ее функционал за счет API, доступного сторонним разработчикам. Этот шаг резко увеличил объем слов, ежедневно обрабатываемых системой, и продемонстрировал возможности краудсорсинговой идентификации контента не только для улучшения мер цифровой безопасности, но и для содействия крупномасштабным проектам оцифровки. Эта инициатива обозначила переход к использованию усилий интернет-пользователей для достижения широких технологических и культурных целей.
Заключение
Даже такая простая технология, как капча, имеет сложную нелинейную историю. Возникнув как препятствие атакам ботов, эта технология стала важным инструментом в оцифровке текстовых архивов самых разных направлений. Постепенное расширение функционала капчи связано не только с приумножением ее разновидностей (от GIMPY, BONGO, PIX и ECO до reCAPTCHA), но и с привлечением вычислительных мощностей рядовых пользователей. Так технология интернет-безопасности вовлекает людей и машин в совместную работу.





